GLM-5大模子官宣支撑7大国产芯片平台,华为、寒武纪、摩尔线程等在列
时间:2026-02-23 12:53:53
小编:china
阅读:
2月22日消息,春节期间国产AI大模型轮番登场,除了DeepSeek V4还在低调之外,几家热门模型都来了,其中智谱的GLM-5是其中热度最高的之一。
从智谱官网介绍来看,GLM-5重点就是提升编程与智能体能力,其参数量达到了7440亿,是上代GLM-4.X的2倍左右,性能提升很明显。
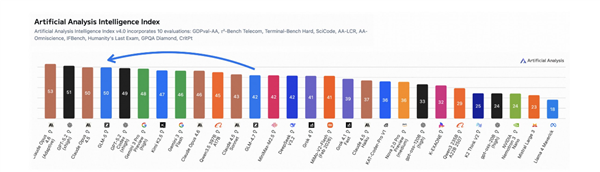
此前有海外的AI博主测试其代理编程能力世界第一,综合编程能力世界第三,仅次于Opus 4.6及Gemini 3 Pro,但超越了Opus 4.5。
发布之后由于太受欢迎,导致GLM-5需求暴涨,甚至导致算力不够,用户体验下滑,为此智谱还发布了道歉信,并给出了补偿方案,其能力表现可见一斑。
今天智谱还发布了GLM-5大模型的技术报告,特别提到了性能提升主要来自于四大技术创新,具体如下:
1、引入DSA稀疏注意力机制(DeepSeek Sparse Attention, DSA),极大降低了训练与推理成本。
此前的GLM-4.5依赖标准MoE架构提升效率,而DSA机制则使GLM-5能够根据Token的重要性动态分配注意力资源。在不折损长上下文理解和推理深度的前提下,算力开销得以大幅削减。
得益于此,智谱将模型参数规模扩展至 744B,同时将训练Token规模提升至28.5T。
2、构建全新的异步RL基础设施
基于GLM-4.5时期 slime 框架训练与推理解耦”的设计,智谱的新基建进一步实现了生成与训练”的深度解耦,将GPU利用率推向极致。系统支持模型开展大规模的智能体(Agent)轨迹探索,大幅减缓了以往拖慢迭代速度的同步瓶颈,让RL后训练流程的效率实现了质的飞跃。
3、提出全新的异步Agent RL算法
该算法旨在全面提升模型的自主决策质量。GLM-4.5曾依靠迭代自蒸馏和结果监督来训练Agent;而在GLM-5中,研发的异步算法使模型能够从多样化的长周期交互中持续学习。
这一算法针对动态环境下的规划与自我纠错能力进行了深度优化,这也正是GLM-5能够在真实编程场景中表现卓越的底层逻辑。
4、全面拥抱国产算力生态
从模型发布伊始,GLM-5就原生适配了中国GPU生态。智谱已完成从底层内核到上层推理框架的深度优化,全面兼容七大主流国产芯片平台:华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、天数智芯与燧原。
据介绍,GLM-5在单台国产算力节点上的性能表现,已足可媲美由两台国际主流GPU组成的计算集群,不仅如此,在长序列处理场景下,其部署成本更是大幅降低了 50%。

-
 GLM-5大模子官宣支撑7大国产芯片平台,华为、寒武纪、摩尔线程等在列2月22日消息,春节期间国产AI大模型轮番登场,除了DeepSeek V4还在低调之外,几家热门模型都来了,其中智谱的GLM-5是其中热度最高的之一。时间:2026-02-23
GLM-5大模子官宣支撑7大国产芯片平台,华为、寒武纪、摩尔线程等在列2月22日消息,春节期间国产AI大模型轮番登场,除了DeepSeek V4还在低调之外,几家热门模型都来了,其中智谱的GLM-5是其中热度最高的之一。时间:2026-02-23 - 英国硬盘价钱高得让人飞到美国购置,逾越半个地球竟省一大笔钱2月23日消息,英国硬盘价格高得离谱,一网友竟选择跨洋飞往美国采购。即便算上往返机票、酒店等全部开销,最终仍节省超2000美元。Reddit论时间:2026-02-23
-
 打击7GHz、24中心,AMD Zen6将有7种分歧配置2月23日消息,AMD、Intel的下一代桌面CPU处理器都推迟到了2027年,但等待将是值得的,双方都会迎来一次飞跃,到时候内存价格也应该会下来了时间:2026-02-23
打击7GHz、24中心,AMD Zen6将有7种分歧配置2月23日消息,AMD、Intel的下一代桌面CPU处理器都推迟到了2027年,但等待将是值得的,双方都会迎来一次飞跃,到时候内存价格也应该会下来了时间:2026-02-23 - 最有爱的城市在山东,连高铁站都“会比心”2月23日消息,在山东,有一座城市,不止有闻名全国的烟火气”,还有铺满全城的爱心”,堪称最有爱”的城市。坐高铁来山东淄博,体验这份独时间:2026-02-23
-
 烧了540亿,机械人进入“吃鸡游戏”拐点声明:本文来自于微信公众号 智能相对论(ID:aixdlun),作者:叶远风,授权站长之家转载发布。毫无疑问,2026年春晚是机器人“存在感”最强时间:2026-02-22
烧了540亿,机械人进入“吃鸡游戏”拐点声明:本文来自于微信公众号 智能相对论(ID:aixdlun),作者:叶远风,授权站长之家转载发布。毫无疑问,2026年春晚是机器人“存在感”最强时间:2026-02-22



热门阅读
-
哥哥抚慰腮腺炎弟弟 得知传染秒变脸
阅读:34
-
999元起,联想moto g100s开售,LCD护眼屏、支撑微信/抖音6开
阅读:29
-
电力除冰“小黄人”爆火 刷屏海内外社交平台
阅读:21
-
王自若称买超薄手机苹果必然是选,安卓都是缝合怪 不如苹果
阅读:21
-
阅读:20





